Исследование моделей
После того как модели обработаны, вы можете просмотреть их, используя закладку Mining Model Viewer в редакторе Data Mining. При помощи выпадающего списка Mining Model в верхней части закладки можно исследовать модели, входящие в структуру.
Модель Microsoft Decision Trees
Mining Model Viewer по умолчанию открывает модель Targeted Mailing первой в структуре.
Tree viewer содержит две закладки, Decision Tree (дерево решений) и Dependency Network (сеть зависимостей).
Decision Tree (Дерево решений)
На странице Decision Tree вы можете просмотреть все модели деревьев, составляющие модель Targeted_Mailing. Для каждого прогнозируемого атрибута модели существует одно дерево, если только не задействовано feature selection. Так как ваша модель содержит всего один прогнозируемый атрибут, Bike Buyer, то и дерево тоже одно. Если бы их было несколько, можно было бы выбрать нужное при помощи Tree box.
Tree viewer по умолчанию показывает только первые три уровня дерева. Чтобы увидеть больше используйте Show Level slider или Default Expansion box. Для более подробной информации по настройке Tree viewer, обратитесь к разделу "Viewing with Tree Viewer" в SQL Server Books Online.
Чтобы создать дерево, показанное на рисунке 6
- Установите Show Level 5
- В списке Background нажмите 1.
Здесь задаётся состояние прогнозируемого атрибута. Изменяя это свойство, вы можете быстро узнать число случаев попадания покупателя велосипеда в каждый узел. Чем темнее узел, тем больше случаев попадания он содержит.
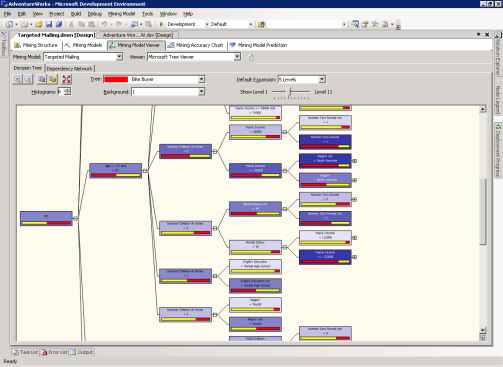
Рисунок 6 Страница Decision Tree для модели Targeted Mailing
Каждый узел в дереве решений несёт в себе следующую информацию:
- Условие, по которому попадаем в этот узел из предыдущего. Полный путь к узлу можно узнать из легенды или из подсказки.
- Гистограмма, описывающая распределение состояний для прогнозируемого столбца. Число состояний, отображаемых на гистограмме, регулируется при помощи Histogram control.
- Концетрацию случаев попадания, если состояние предсказываемого значения определено в контроле Background.
Если включен режим drillthrough ("проваливание" в исходные данные), вы можете просмотреть варианты для узла, кликнув по нему правой кнопкой мыши и выбрав Drillthrough.
Сеть зависимостей (Dependency Network)
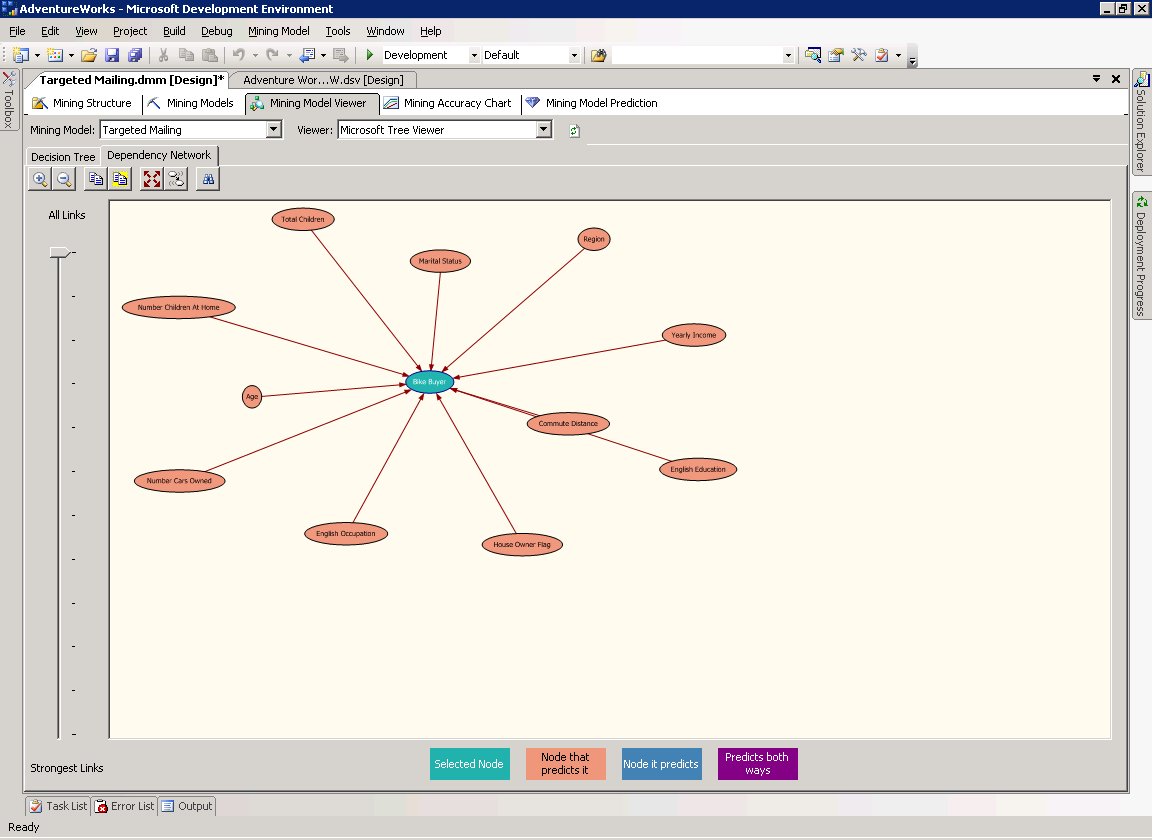
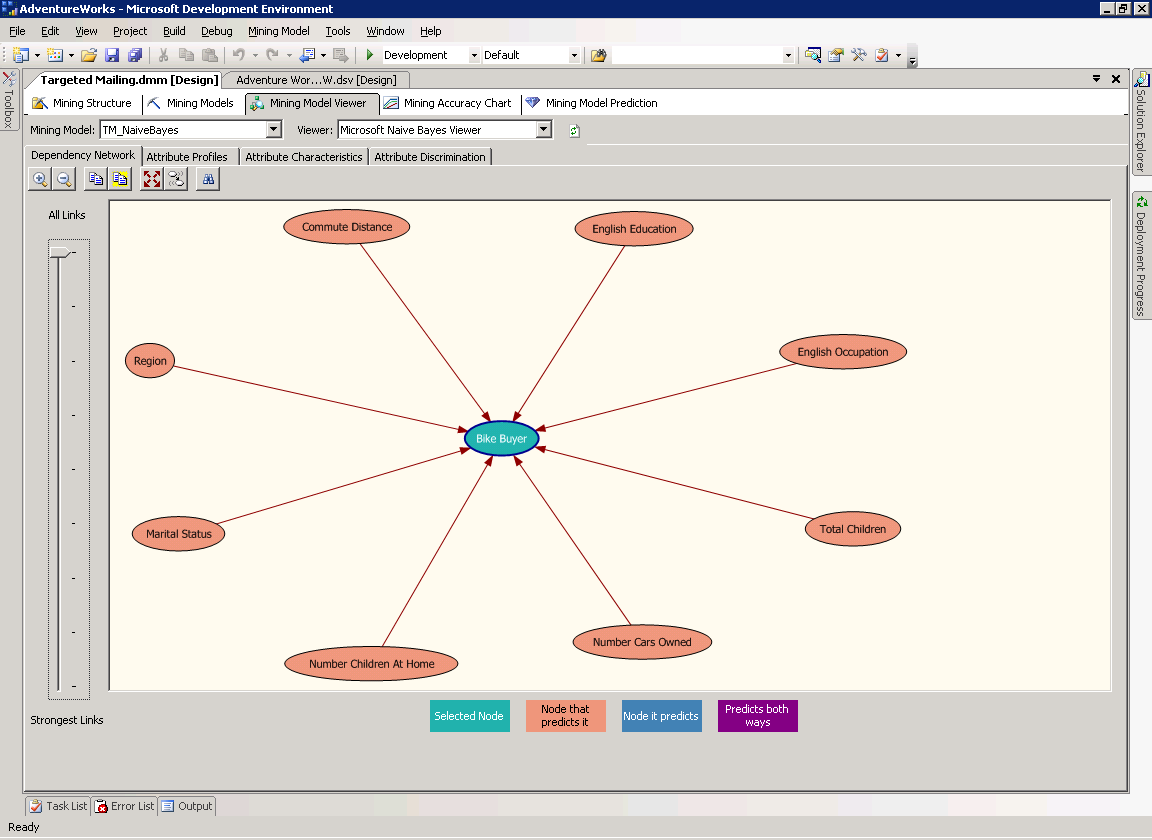
На странице Dependency Network показаны отношения между атрибутами, влияющими на прогнозирующую способность модели. Сеть зависимостей для модели Targeted Mailing представлена на рисунке 7.
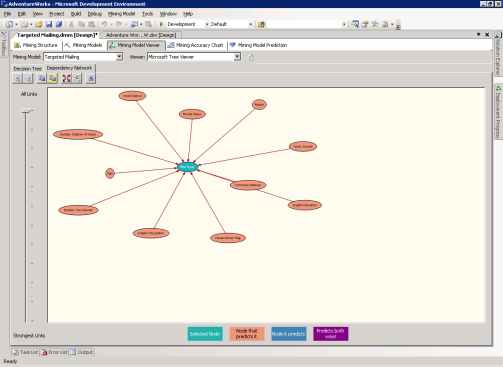
Рисунок 7 Страница Dependency Network модели Targeted Mailing.
Центральный узел на рисунке 7, Bike Buyer, представляет прогнозируемый атрибут модели. Каждый из узлов вокруг него отображает атрибут, влияющий на прогнозируемый. При помощи ползунка на левой стороне страницы можно указать силу показываемых связей. При перемещении ползунка вниз будут показываться только сильные связи.
По легенде цветов внизу окна можно узнать, какой узел является прогнозируемым и какие узлы его определяют.
Модель Microsoft Clustering
Используйте combo box Mining Model для перехода к модели TM_Clustering. Окно этой модели, Cluster viewer, содержит четыре закладки: Cluster Diagram, Cluster Profiles, Cluster Characteristics, и Cluster Discrimination. По умолчанию при первом открытии отображается страница Cluster Diagram.
Для более подробной информации по использованию Cluster viewer, обратитесь к разделу " Viewing with Cluster Viewer " в SQL Server Books Online.
Кластерная диаграмма (Cluster Diagram)
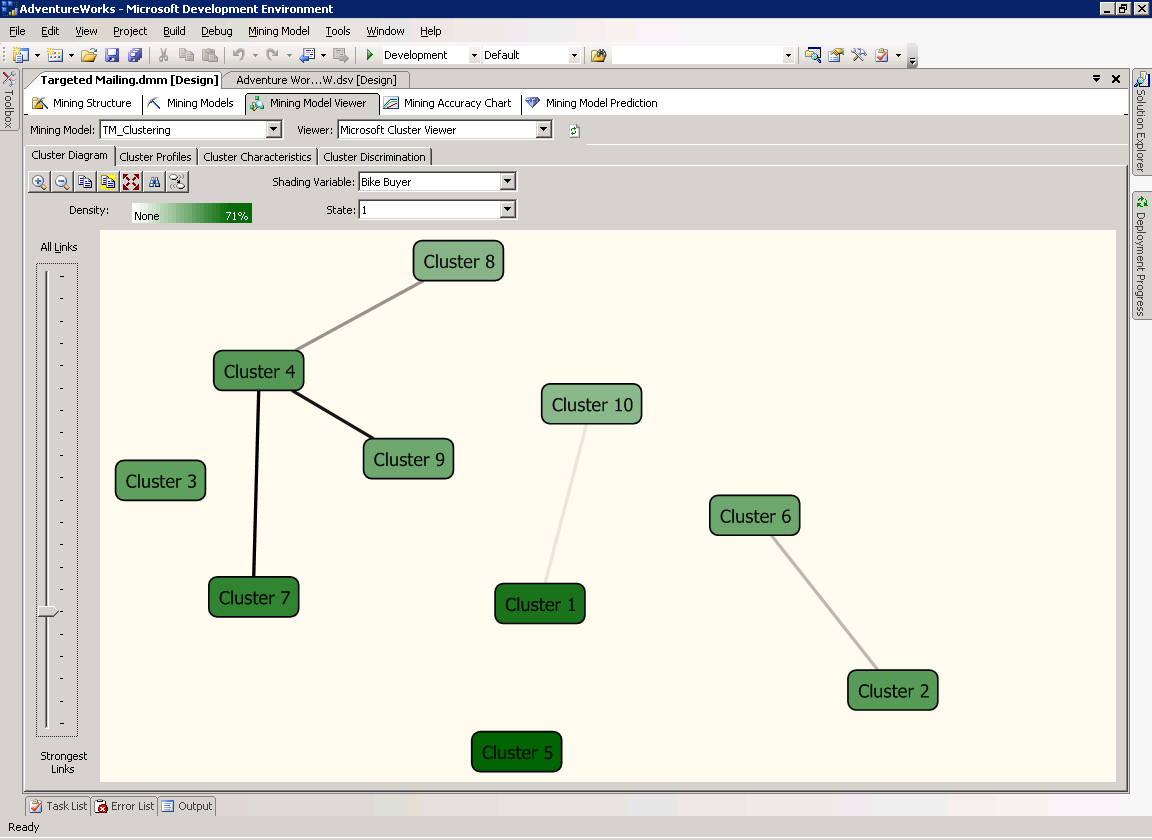
На странице Cluster Diagram вы можете изучить отношения между кластерами, обнаруженными алгоритмом. Длина линий, соединяющих кластеры, отображает "близость", а их интенсивность показывает, насколько они схожи. Цвет кластера отвечает за частоту появления переменной и состояния (выбранные в полях Shading Variable и State вверху экрана) в каждом кластере. Переменная по умолчанию population, но вы можете поменять её на любую другую из модели и найти нужные вам кластеры. Используя полосу прокрутки в левой части экрана, вы можете отфильтровать слабые связи и найти кластеры, расположенные наиболее близко к друг другу.
Например, установите поле Bike Buyer в качестве Shading Variable и State в 1. Как показано на рисунке 8, кластер №5 содержит наибольшее число покупателей велосипедов. А самая сильная связь - между 4 и 7 кластерами.
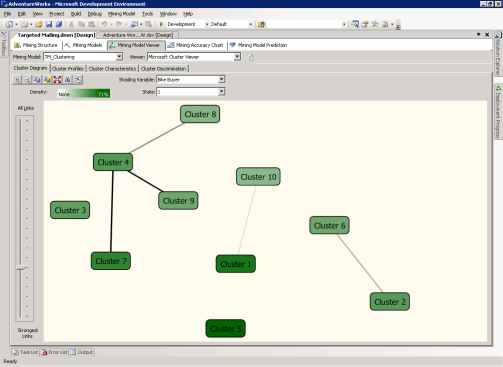
Рисунок 8 Кластерная диаграмма модели TM_Clustering.
Профили кластеров (Cluster Profiles)
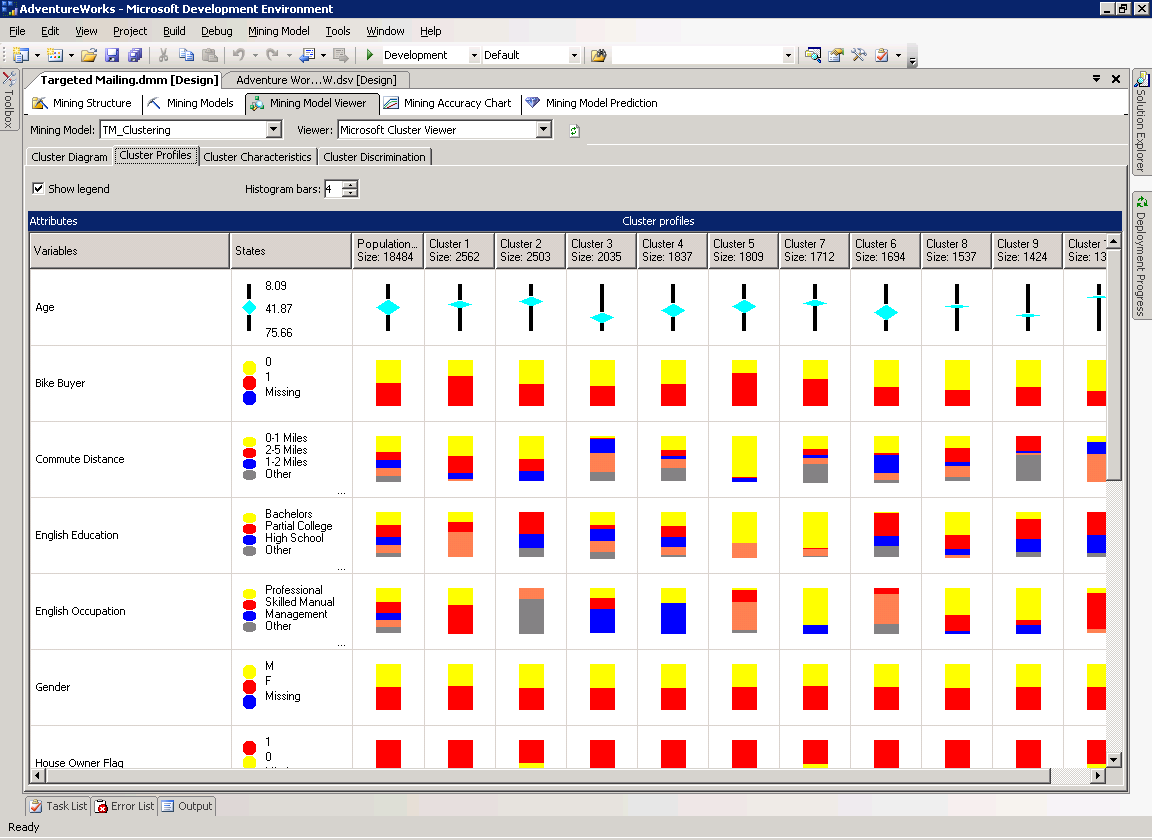
Страница Cluster Profiles предоставляет общий вид модели TM_Clustering. Как показано на рисунке 9, каждому кластеру модели на этой странице соответствует столбец с описывающими его данными. В первом столбце находится список атрибутов, с которыми связан по крайней мере один кластер. Все оставшиеся столбцы отображают распределение состояний этих атрибутов для каждого кластера. Распределение дискретной переменной показывается цветным столбцом, максимальное число отображаемых цветов-состояний определяется в поле Bars per histogram. Непрерывные значения отображаются diamond диаграммой, показывающей среднее и стандартное отклонение в каждом кластере.
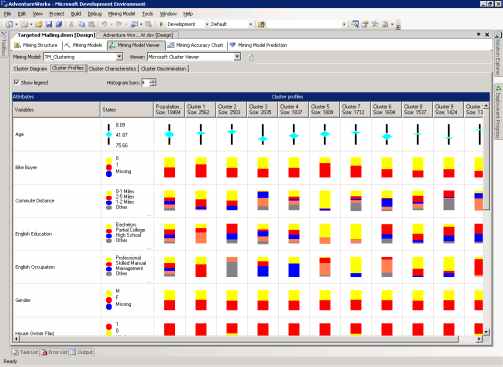
Рисунок 9 Страница Cluster Profiles модели TM_Clustering.
Характеристики кластеров (Cluster Characteristics)
Cтраница Cluster Characteristics позволяет более детально рассмотреть характеристики кластера. Для примера, на рисунке 10, вы можете видеть, что люди из Кластера №5 (покупатели велосипедов) обладают следующими характеристиками: они передвигаются на короткие дистанции (0-1 миля), у них нет машины и они женаты.
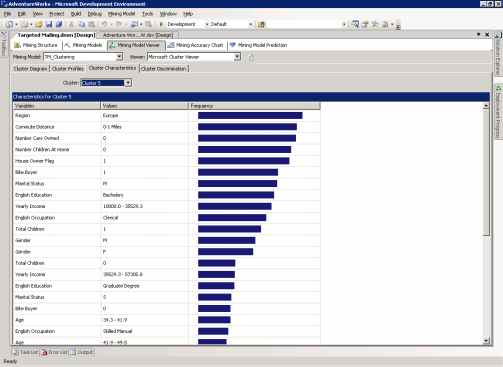
Рисунок 10 Окно характеристик кластера модели TM_Clustering.
Cluster Discrimination
На странице Cluster Discrimination вы можете посмотреть характеристики, отличающие один кластер от другого. После выбора кластеров (поля First cluster и Second cluster) система определяет различия и показывает их, сортируя по атрибутам, наиболее сильно отличающим кластеры.
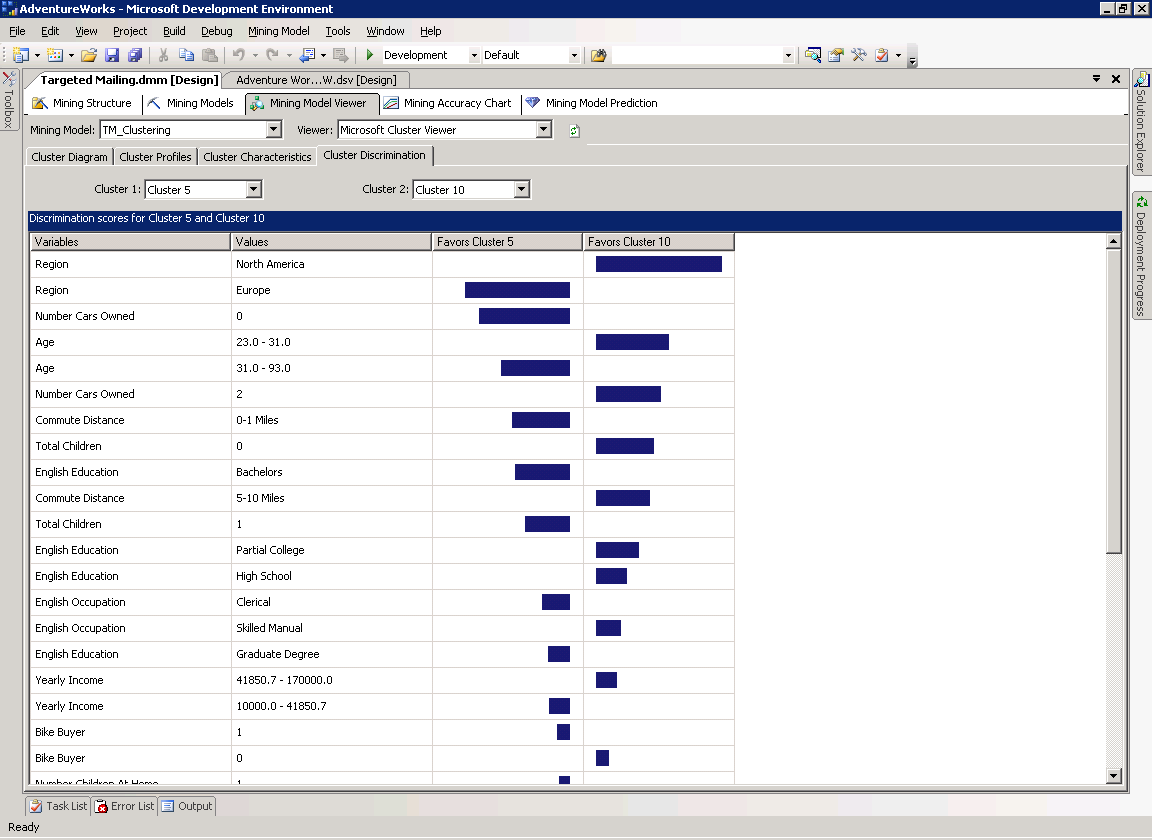
На рисунке 11 приведено сравнение Кластера №5 и Кластера №7 модели TM_Clustering. В кластере №5 наиболее высокая плотность покупателей велосипедов, а в №10, напротив, самая низкая. Видно, к примеру, что люди, попавшие в Кластер №10 скорее всего из Северной Америки и моложе (23-31), чем жители Европы из Кластера №5.
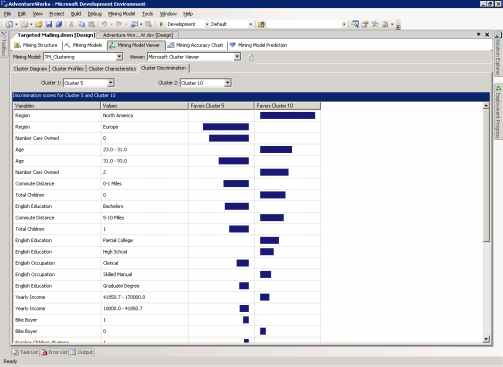
Рисунок 11 Страница Cluster Discrimination модели TM_Clustering.
Модель Microsoft Na?ve Bayes
Используйте выпадающий список Mining Model для перехода к модели TM_NaiveBayes. Окно этой модели, Na?ve Bayes viewer, содержит четыре закладки: Dependency Network, Attribute Profiles, Attribute Characteristics, и Attribute Discrimination.
Для более подробной информации по использованию Na?ve Bayes viewer, обратитесь к разделу " Viewing with Na?ve Bayes viewer " в SQL Server Books Online.
Сеть зависимостей (Dependency Network)
Страница Dependency Network в Na?ve Bayes viewer организована также как одноимённая страница в Tree viewer. Каждый узел представляет атрибут, а линии, связывающие узлы соответствуют отношениям. На рисунке 12 показаны все атрибуты, влияющие на состояние прогнозируемого атрибута, Bike Buyer.
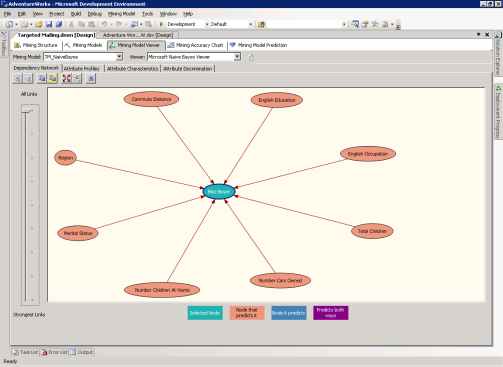
Рисунок 12 Страница Dependency Network для модели TM_Na?veBayes.
По мере передвижении ползунка вниз, остаются атрибуты, наиболее сильно влияющие столбец Bike Buyer (являющийся прогнозируемым). Действуя таким образом, вы обнаружите, что самым сильным фактором, определяющим, купит ли человек велосипед, является число принадлежащих ему машин.
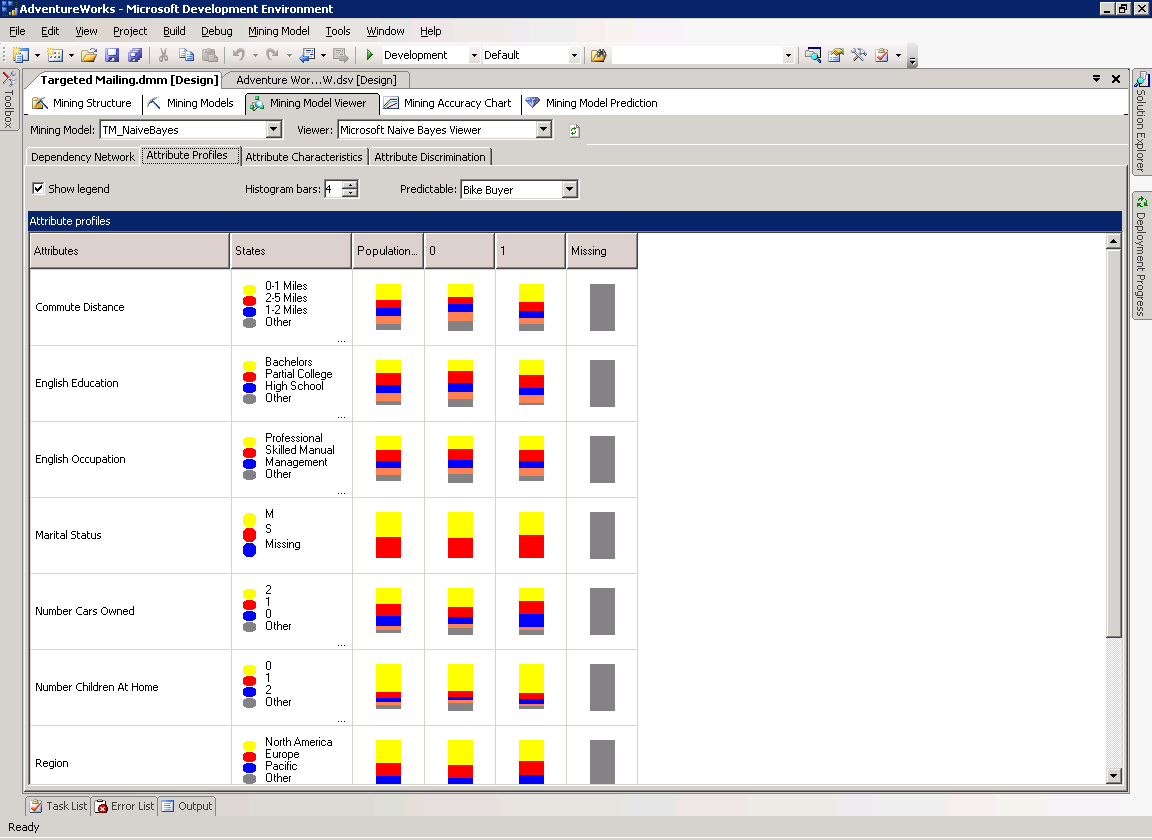
Профили атрибута (Attribute Profiles)
Страница Attribute Profiles описывает как различные состояния входных атрибутов влияют на значение прогнозируемого атрибута.
В поле Predictable выберите Bike Buyer. Атрибуты, влияющие на состояние прогнозируемого атрибута, перечислены вместе со значениями каждого состояния входных атрибутов и их распределениями для каждого состояния прогнозируемого атрибута.
В поле Predictable выберите Bike Buyer. Атрибуты, влияющие на состояние прогнозируемого атрибута, перечислены для всех значений входных параметров совместно с их распределением для каждого состояния прогнозируемого атрибута.
На рисунке 13 показана страница Attribute Profiles для столбца Bike Buyer для модели TM_NaiveBayes model.
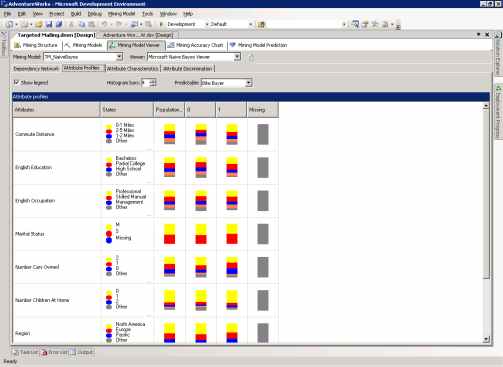
Рисунок 13 Страница Attribute Profiles для модели TM_Na?veBayes.
Характеристики атрибута (Attribute Characteristics)
Используя страницу Attribute Characteristics, вы можете выбрать атрибут и его значение, чтобы увидеть, значения каких атрибутов меняются при этом в большей или меньшей степени.
В поле атрибут выберите Bike Buyer, в поле значение - 1.
Например, из рисунка 14 видно, что люди, не имеющие детей, покупают наибольшее количество велосипедов.
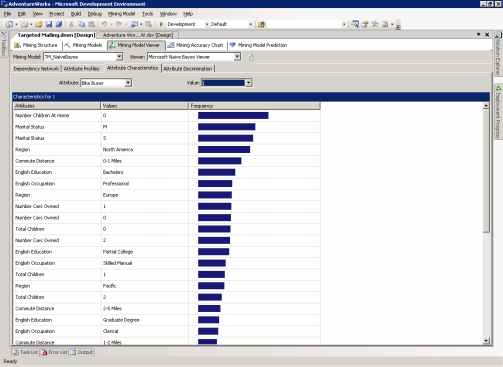
Рисунок 14 Страница Attribute Characteristics для модели TM_Na?veBayes.
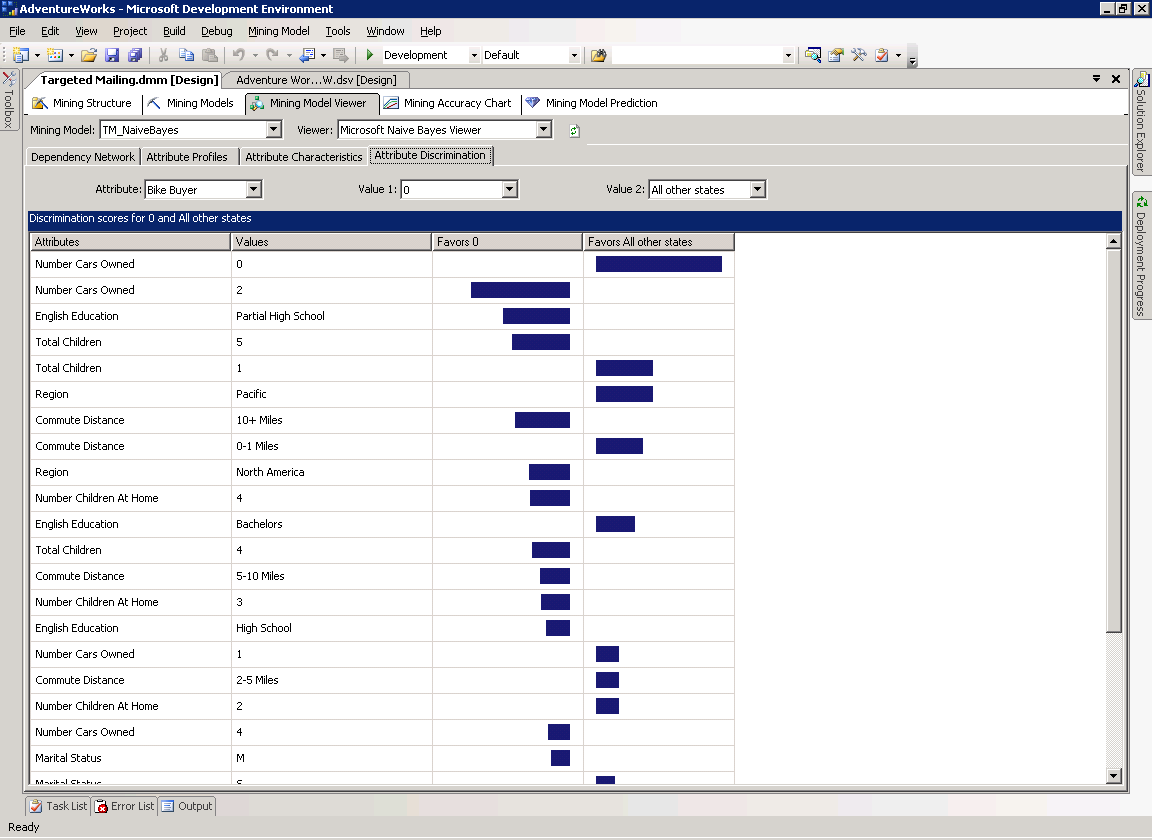
Attribute Discrimination
На странице Attribute Discrimination вы можете исследовать отношение между двумя дискретными значениями выбранного прогнозируемого атрибута и значениями других атрибутов.
Поскольку модель TM_NaiveBayes имеет всего два состояния, 1 и 0, вам не придётся совершать каких-либо дополнительных действий по настройке окна.
К примеру, из рисунка 15 видно, что те, у кого нет машины более склонны к покупке велосипеда, а люди, имеющие две машины скорее не будут этого делать.
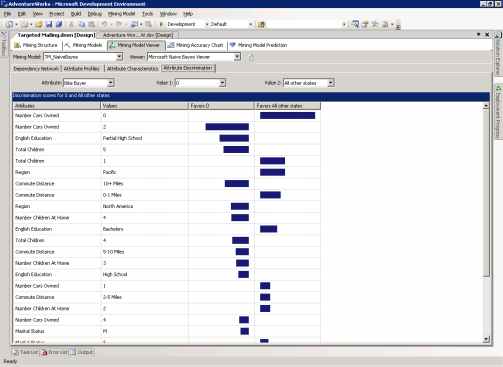
Рисунок 15 Страница Attribute Discrimination для модели TM_NaiveBayes.
|