Кластеризация последовательностей
Отдел маркетинга компании Adventure Works хочет знать, каким образом покупатели перемещаются по их корпоративному сайту. Они подозревают, что существует некий шаблон, в соответствии с которым покупатели кладут товары в свои корзины. Используя алгоритм Microsoft Sequence Clustering, они могут определить последовательности в которых покупатели совершают покупки. Они могут использовать эту информацию для изменения расположения информации на сайте, тем самым, стимулировав клиентов к дополнительным покупкам.
После решения этой задачи, отдел маркетинга будет располагать моделью, способной предсказывать, что покупатель следующим положит в свою корзину.
Для выполнения этой задачи, аналитик будет использовать алгоритм Microsoft Sequence Clustering. Сценарий состоит из двух подзадач:
- Создание структуры модели Data Mining.
- Исследование модели.
Создание структуры модели кластеризации последовательностей при помощи мастера
Первый шаг заключается в использовании мастера Mining Model Wizard для создания новой структуры Data Mining. При этом также создаётся начальная модель, основанная на алгоритме Microsoft Sequence Clustering.
Для того чтобы создать структуру модели
- В Solution Explorer кликните правой кнопкой мыши на Mining Models, выберите New Mining Model.
Откроется Mining Model Wizard.
- Нажмите Next на странице приветствия.
- Выберите From existing relational database or data warehouse, затем Next.
- В разделе Which data mining technique do you want to use? выберите Microsoft Sequence Clustering.
- Нажмите Next.
По умолчанию в качестве источника данных здесь выбран Adventure Works DW.
- Пометьте флагом Case таблицу vAssocSeqOrders и флагом Nested таблицу vAssocSeqLineItems, затем нажмите Next.
- Пометьте флагом Key столбец CustomerKey.
По умолчанию, поля OrderNumber и LineNumber являются Key полями, что в данном случае правильно.
- Пометьте флагом Input и Predictable столбец Model.
- Нажмите Next.
- Нажмите Next.
- В поле Model Name введите Sequence Clustering, после чего нажмите Finish.
Откроется редактор Data Mining, показывая созданную вами структуру Data Mining.
Рисунок 32 Структура Sequence Clustering.
Вам не нужно вносить каких бы то ни было изменений в структуру или саму модель, так что можете просто провести процессинг.
Обработка модели
Обработка модели производится таким же образом, как и для модели целевой рассылки. Для дополнительной информации обратитесь к разделу "Адресная рассылка" этого документа.
Исследование модели
Чтобы открыть Sequence Clustering viewer, выберите страницу Mining Model Viewer.
Подобно Cluster viewer, Sequence Clustering viewer содержит закладки: Cluster Diagram, Cluster Profiles, Cluster Characteristics, Cluster Discrimination и State Transitions. Для более подробной информации по использованию Sequence Clustering viewer, обратитесь к разделу " Viewing with Sequence Clustering viewer " в SQL Server Books Online.
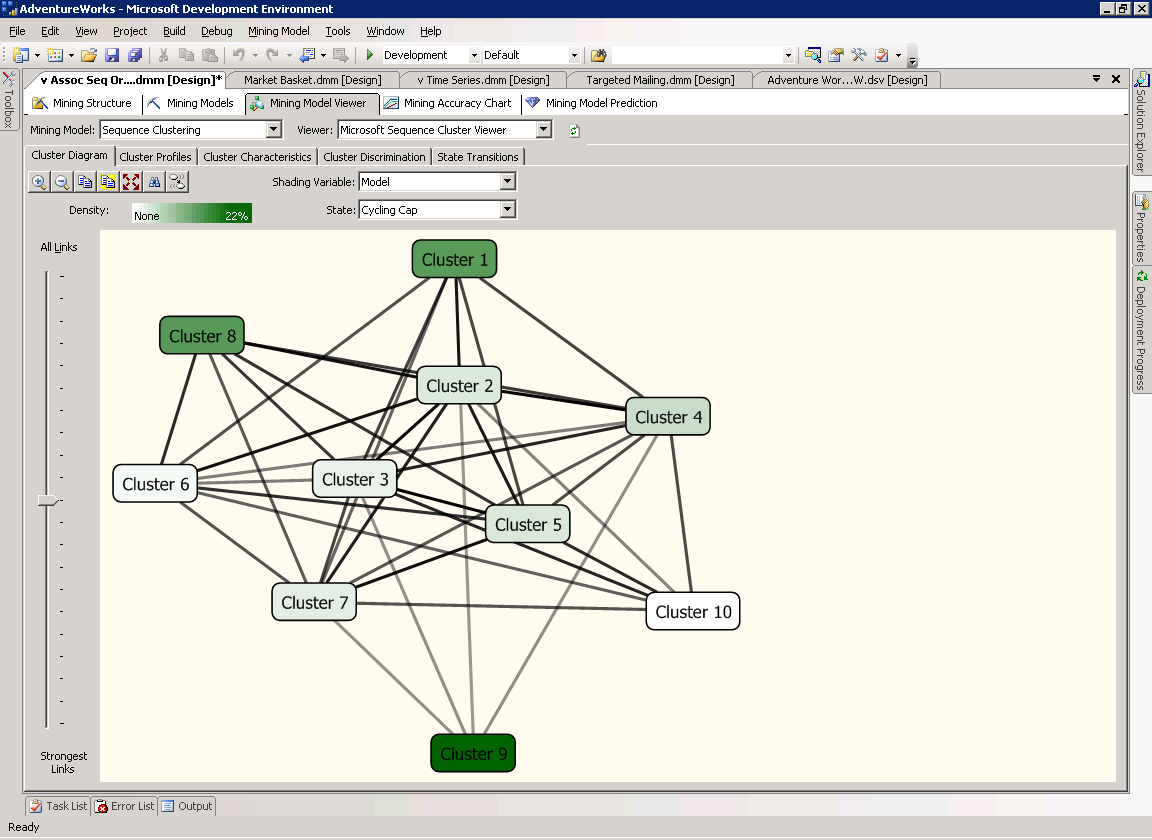
Диаграмма кластеров - Cluster Diagram
На странице Cluster Diagram графически отображаются обнаруженные алгоритмом кластеры. Расположение отвечает взаимосвязям между кластерами, схожие узлы расположены рядом. По умолчанию, цвет кластера показывает плотность всех случаев попадания в кластере - более тёмные узлы содержат больше случаев. Вы можете поменять значение цветовой индикации узлов, чтобы она отображала переменную и состояние. Например, чтобы получить диаграмму, показанную на рисунке 33, в списке Shading Variable выберите Model, а в списке State выберите Cycling Cap.
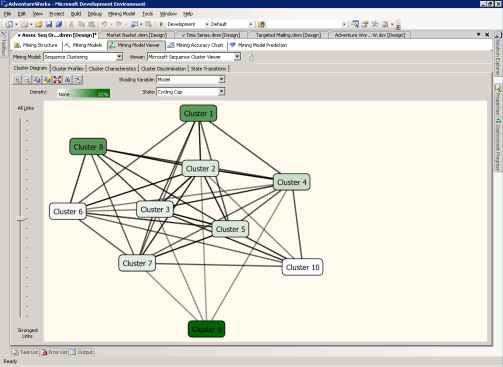
Рисунок 33 Кластерная диаграмма модели Microsoft Sequence Clustering.
Видно, что кластер 9 обладает наибольшей плотностью велосипедных шлемов (cycling cap).
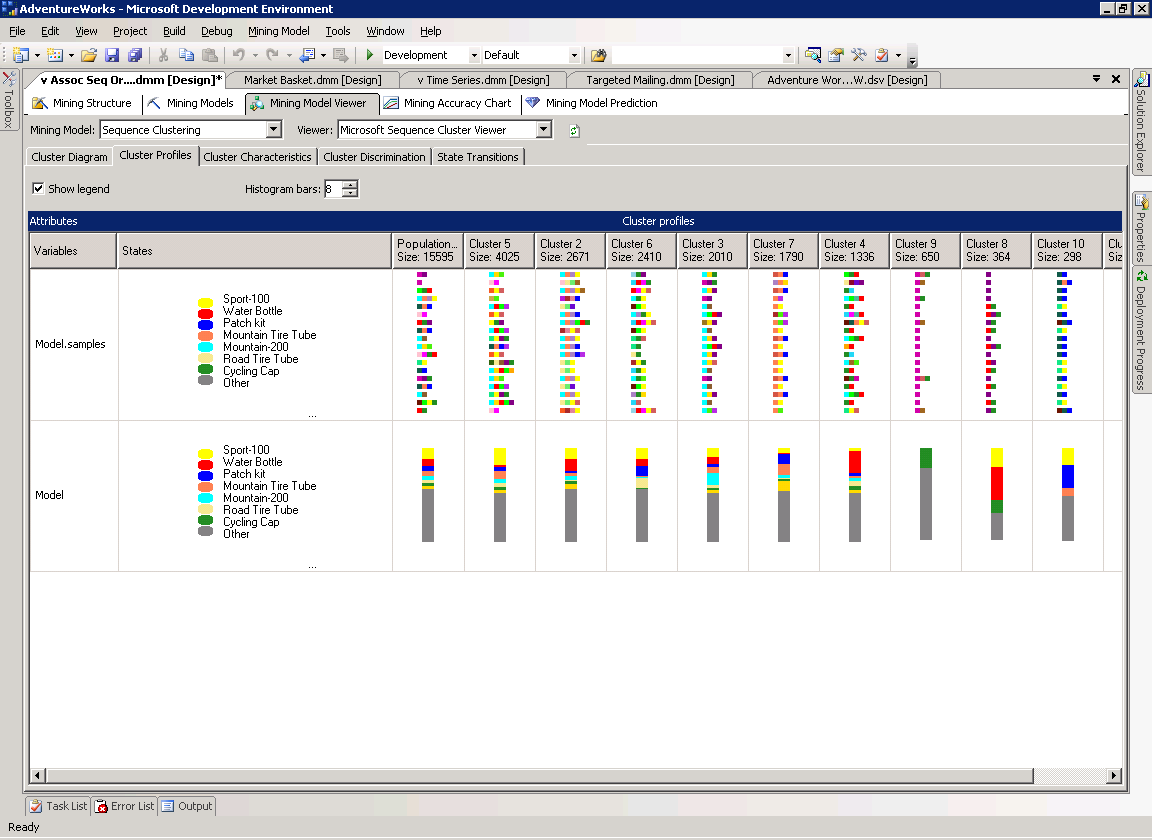
Профили кластеров (Cluster Profiles)
На странице Cluster Profiles показаны последовательности, существующие для каждого кластера. Кластеры перечислены в отдельных колонках справа от столбца States, в строках расположены распределения переменной, указанной в столбце Variables.
На рисунке 34, строка Model.samples представляет последовательность, а строка Model описывает общее распределение атрибутов в кластере. Каждая линия в цветовой последовательности, показываемой в ячейках строки Model.samples отвечает поведению случайно выбранного покупателя в кластере. Каждому цвету соответствует какой-либо товар.
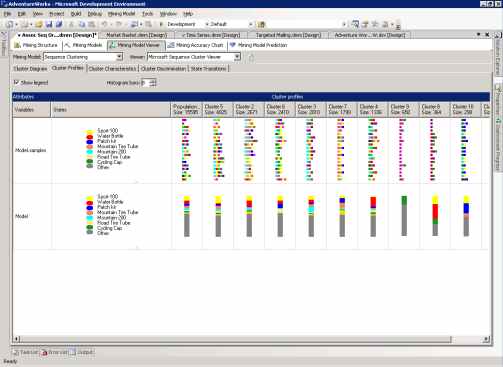
Рисунок 34 Страница Cluster Profiles модели Microsoft Sequence Clustering.
Например, цвет морской волны в кластере 3 представляет велосипед Mountain-200. Он присутствует на первом месте во многих последовательностях, из чего можно сделать вывод, что покупатель скорее всего купит его первым.
Характеристики кластеров - Cluster Characteristics
Cтраница Cluster Characteristics суммирует переходы между состояниями в кластере, длина полос описывают важность значения атрибута в выбранном кластере. Например, для кластера 10, видно, что покупатели здесь склонны положить ML Mountain tire в свои корзины в первую очередь.
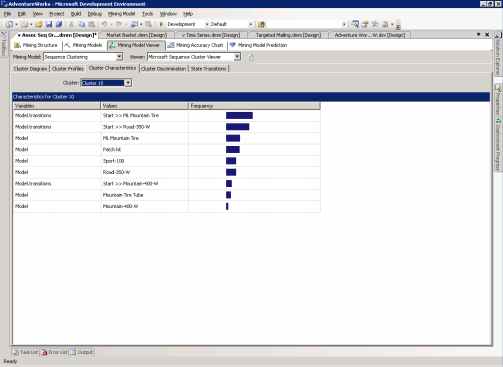
Рисунок 35 Окно характеристик кластера модели Microsoft Sequence Clustering.
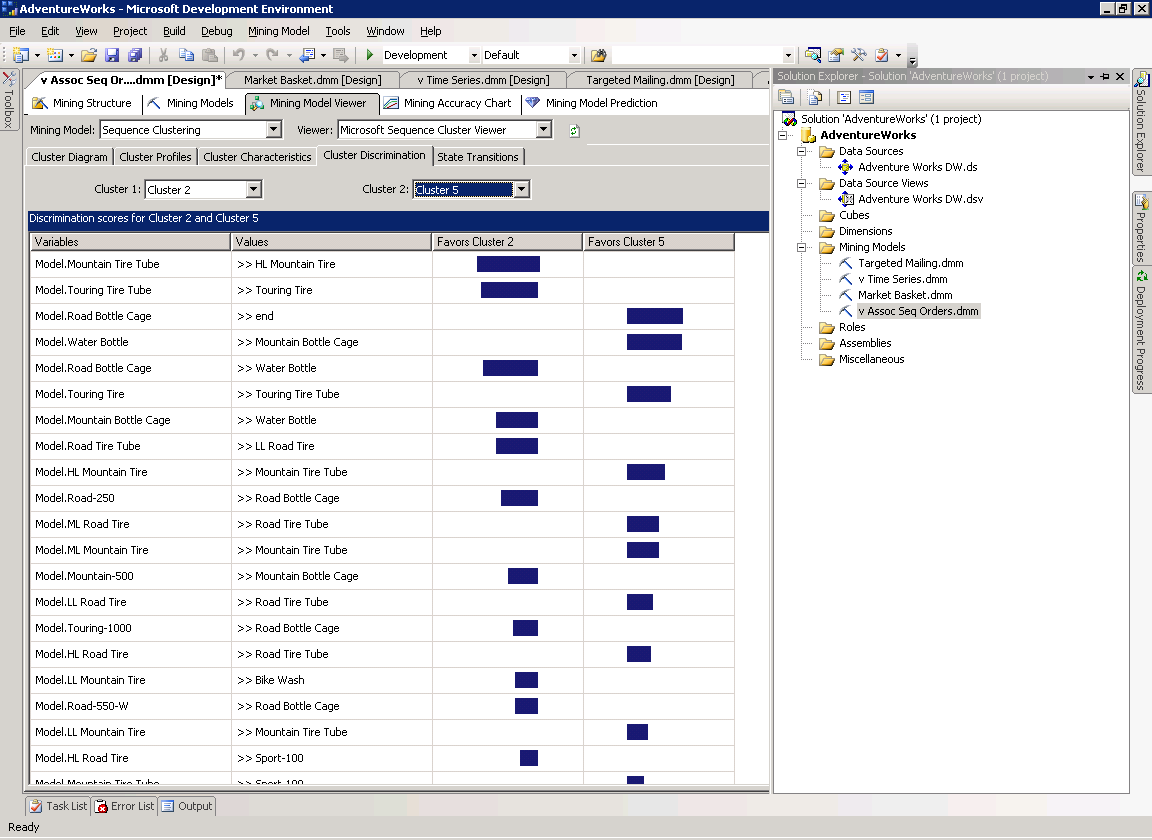
Cluster Discrimination
На странице Cluster Discrimination вы можете сравнить два кластера, определяя какие товары являются в них наиболее популярными. Страница содержит четыре колонки: Variables, Values, Favor Cluster (i), Favor Cluster (i).
Например, на рисунке 36 сравниваются кластер 2 и кластер 5. Клиент, купивший чехол для бутылки для горного велосипеда (обозначено как Mountain Bottle Cage в столбце Values) с большей вероятностью относится к кластеру 5, а покупателя, купивший Touring Fire (обозначено как Touring Fire в столбце Values) скорее можно отнести к кластеру 2.
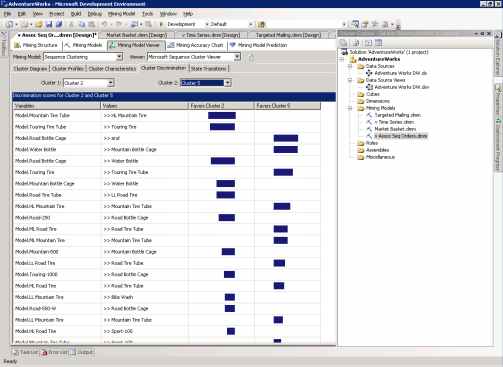
Рисунок 36 Страница Cluster Discrimination модели Microsoft Sequence Clustering.
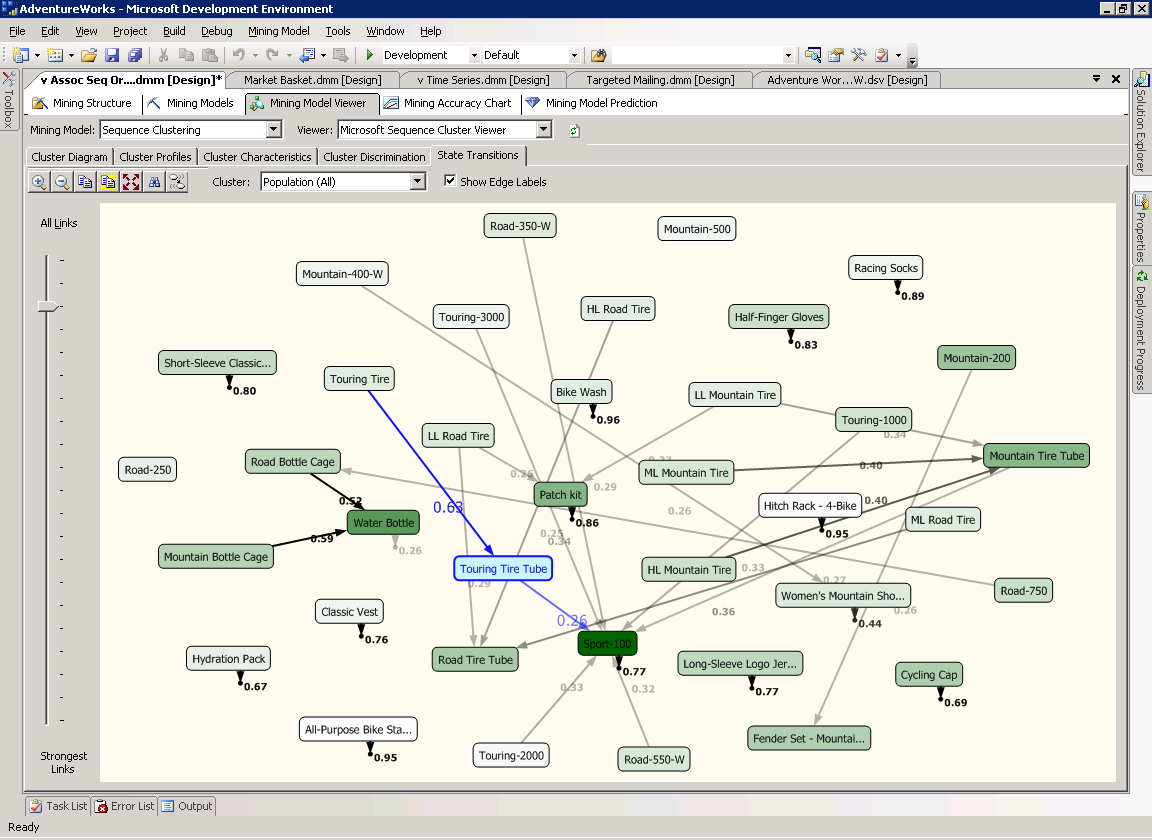
Переходы между состояниями - State Transitions
На странице State Transitions, вы можете выбрать кластер и проследить переходы его состояний. Каждый узел отвечает состоянию модели (как Mountain-200). Связующие линии отображают переходы между состояниями, и каждому узлу соответствует вероятность перехода. Цвет узла представляет частоту появления узла в кластере.
Например, выберите Cluster 3, затем узел Touring-3000 и переместите полоса прокрутки All Links немного вниз. Как вы можете увидеть на рисунке 37, если клиент добавляет Touring Fire в свои корзины, то с вероятностью 0,63 (показана синей стрелкой) он возьмёт затем Touring Fire Tube, и с вероятностью 0,26 он закончит покупки, добавив в корзину велосипед Sport 100.
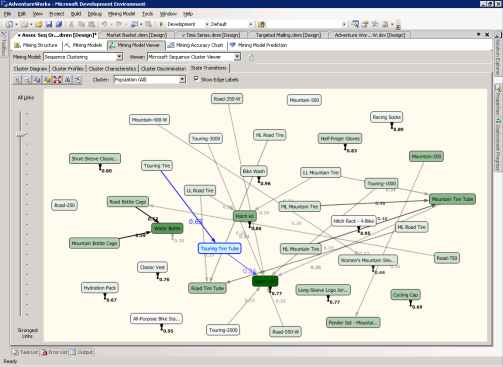
Рисунок 37 Страница Cluster Transitions модели Microsoft Sequence Clustering.
|





 Покупательская корзина
Покупательская корзина
 Алгоритмы Data Mining - Приложение A
Алгоритмы Data Mining - Приложение A
