Отличия алгоритма дерева решений от ассоциативных правил в задачах классификации
Алгоритм ассоциативных правил предназначен для выявления в данных зависимостей типа A -> B, где A и B представляют собой наборы пар атрибут=значение. Правило должно быть:
- значимым, т.е. наборы A и B должны достаточно часто совместно встречаться в исходных данных;
- точным, т.е. доля записей, содержащих набор B в записях, содержащих набор A, должна быть высока;
- интересным, т.е. наличие набора A в записи должно увеличивать вероятность наличия набора B в этой же записи.
Алгоритм дерева решений предназначен для решения задач регрессии и классификации, т.е. для выявления зависимости целевого параметра от значения других параметров. В процессе построения модели алгоритм итеративно вычисляет степень влияния каждого входного атрибута модели на значения выходного атрибута и использует атрибут, влияющий на выходной атрибут в наибольшей степени для разбиения узла дерева решений. Узел верхнего уровня описывает распределение значений выходного атрибута по всей совокупности данных. Каждый последующий узел описывается распределением выходного атрибута при соблюдении условий на входные атрибуты, соответствующие этому узлу. Модель продолжает расти до тех пор, пока разбиение узла на последующие узлы значительно увеличивает вероятность того, что выходной атрибут будет принимать какое-то определенное значение по сравнению со всеми другими значениями, т.е. разбиение увеличивает качество прогноза. Алгоритм также прекращает разбиение, когда число записей в базе данных, описываемых условиями узла, становится меньше определенного уровня. Алгоритм осуществляет поиск атрибутов и их значений, разбиение по которым позволяет с большей вероятностью правильно предсказать значение выходного атрибута.
Так же, как и в случае с алгоритмом ассоциативных правил, алгоритм дерева решений позволяет выявлять правила в данных типа A -> B. Для этого в качестве левой части правила (условия A) надо объединить условия по всем узлам в ветке дерева от корня до листа, содержащего описание условий на целевую переменную B.
Несмотря на похожесть решаемой задачи и форму представления результата, правила, получаемые обоими алгоритмами, могут существенно
различаться. Все дело в том, что процесс построения дерева решений основан на максимизации прироста информации,
в то время как алгоритм ассоциативных правил основан на выделении частых наборов, в которых частота появления одной части (правая часть правила) относительно наборов, в которых есть другая часть (левая часть правила), высока.
Исходя из приведенного анализа отличия между алгоритмами, мы можем построить пример, приводящий к принципиально различным результатам.
Предположим, что магазин содержит в ассортименте три товара: товар А, товар Б и товар В. Допустим, мы хотим выделить правила, предсказывающие факт покупки товара А. Построим дерево решений. Из всех транзакций (10 000) одна часть (6 000) содержит товар А, а другая (4 000) не содержит. Далее алгоритм дерева решений должен проверить разбиение транзакций по факту наличия товара Б и наличия товара С. Конечное разбиение будет осуществлено по атрибуту, в наибольшей степени увеличивающему прирост информации по факту покупки товара А.
Рассмотрим сначала возможность разбиения по факту покупки товара Б. Предположим, товар Б содержится в 8 000 транзакций. В одной части этих транзакций (4 800) содержится товар А, а в другой (3 200) - нет. Далее, в 2 000 транзакций из тех, что не содержат товар Б, часть (1 200) содержит товар А, а часть (800) -нет. Вариант дерева решений принимает вид:
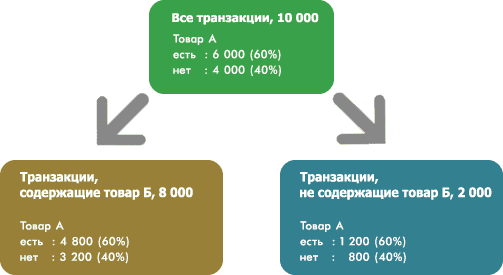
Таким образом, разбиение по наличию товара Б в транзакции не увеличивает прирост информации (распределение транзакций, содержащих товар А сохраняется после разбиения по факту покупки товара Б). Т.е. алгоритм дерева решений не будет осуществлять разбиение по признаку наличия товара Б в транзакции. При этом, алгоритм ассоциативных правил скорее всего сформулирует правило вида товар Б -> товар А, так как транзакции, содержащие одновременно товар А и товар Б являются очень частыми (4 800 или 48% транзакций), а точность соблюдения правила составляет 60%, что часто входит в пороговое значение анализируемых правил в алгоритме ассоциативных правил.
Теперь рассмотрим вариант построения дерева решений с разбиением по факту покупки товара В. Предположим, что 1 000 транзакций содержит товар В, а оставшиеся 9 000 - нет. Из 1 000 транзакций, содержащих товар В, 900 транзакций содержит товар А, а 100 - нет. Из 9 000 транзакций, не содержащих товар В, 5 100 транзакций содержат товар А, а 3 900 - нет. Ниже изображено соответствующее дерево решений
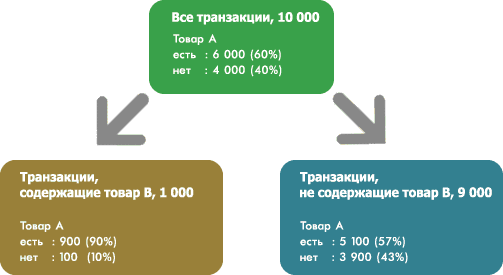
Разбиение по признаку наличия товара В дает в случае положительного ответа значительный прирост информации: 90% транзакций, содержащих товар В, содержат товар А, т.е. дерево решений сформулирует правило товар В -> товар А. Алгоритм ассоциативных правил может не дать аналогичного правила, так как транзакции, одновременно содержащие товары А и В, составляют лишь 9% от общего числа транзакций, что может не пройти порог поддержки правила в алгоритме.
Таким образом, на данных сконструированного примера, алгоритм дерева решений даст правило товар В -> товар А,
а алгоритм ассоциативных правил - товар Б -> товар А.
Выбор алгоритма обнаружения правил в данных может существенно повлиять на результат анализа. Возможное отличие в результатах связано с особенностью реализации каждого из описанных алгоритмов и не является ошибкой одного из них. В этой связи имеет смысл рекомендовать их совместное применение и использование экспертного знания для выбора наиболее адекватного для каждой конкретной модели.
|



